Opendata チームのご紹介
世界中のビジネスデータを再構成しユーザーにインサイトを届ける
StockmarkのOpendata Unitについてご紹介します
🆕News
ハルシネーションを大幅抑止し専門的な質問にも正確な回答が可能な生成AI ストックマーク 1,000億パラメータ規模の独自LLMを公開
⛰️ストックマークが向き合う課題
日本のエンタープライズ企業が抱えるイノベーションの課題
ストックマークが解決する社会課題は、日本の大企業の競争力低下です。
日本企業が世界的に存在感を増すためにはイノベーションの実現が不可欠です。その最前線で働かれている、商品開発・技術開発・事業開発・R&Dといった人たちは、市場のニーズを的確に捉えながら自社のシーズを活かすことが求められます。しかし、情報のスピードが速く膨大にある現代において、人間の力や既存のツールでは対応しきれないのが実態です。

テキストワークに対する課題を効率化することで、イノベーション創出を支援する

💁プロダクト
サービス紹介
ストックマークのサービスは、日英中の3.5万サイトもの膨大な情報網から、自然言語処理を活用して、ニュース/ IR / 特許 / 論文 / 社内資料を解析し、最適な形で情報をお届けし、次世代のイノベーション創出&アイデア創出の仕組みを提供し、新しくビジネスチャンスを発掘する支援を行っております。


Aconnect
社内外の情報をワンストップで届けるAI SaaS
日々生まれる膨大な情報やニュースから、あなたの知るべきことを届け、組織の壁を越えて共有を可能に。事業を創るアイディアの種を見つけることができる、ナレッジシェア推進サービスです。
Stockmark A Technology
AI x ETLを実現するマルチモーダルLLM搭載プラットフォーム
図表を含む非構造データを整理してデータを作り、データを活用できるようにナレッジ化して、社内の業務で使えるようにします。
🏢エンタープライズ企業を中心に300社に導入実績あり

🎥Aconnectのデモ動画
Anewsのプロダクトデモ動画がありますので、こちらからご覧ください!
🏃今後の展開 〜中期ビジョン〜
AI×PaaSのかけ合わせで非連続的成長を実現していく
弊社はこれまで、SaaSプロダクト「Aconnect」を主軸としてにより、国内エンタープライズ企業の情報収集課題を解決する事業を展開してまいりました。今後は「Aconnect」のさらなる強化を図るとともに、LLM技術を基盤とした新規事業「SAT」に注力し、業務における生成AI活用を目指す企業向けに、データ構造化支援・高精度なRAG(Retrieval - Augmented Generation)構築支援・LLM構築支援などの事業展開を進めていきます
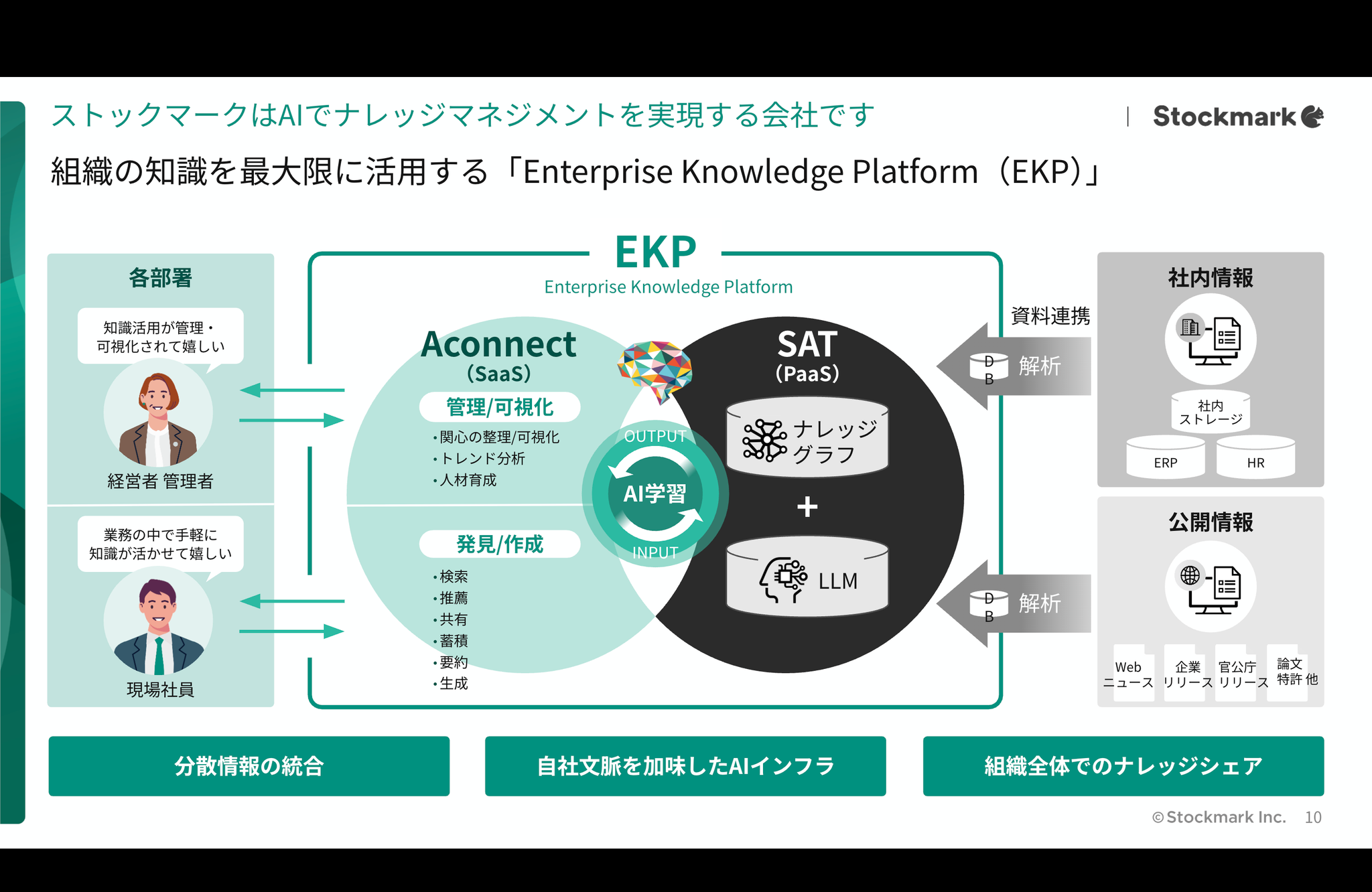
Enterprise Knoledge Platform を目指す
- 社内外の情報がワンストップに検索、推薦され、社内のナレッジシェアが加速し、事業が生まれるエンタープライズナレッジプラットフォームを目指してい参ります。弊社の技術力を基盤にしたLLMやナレッジグラフの研究開発を進め、社内外の「欲しい情報」が一秒で届けられる世界にしていきます。
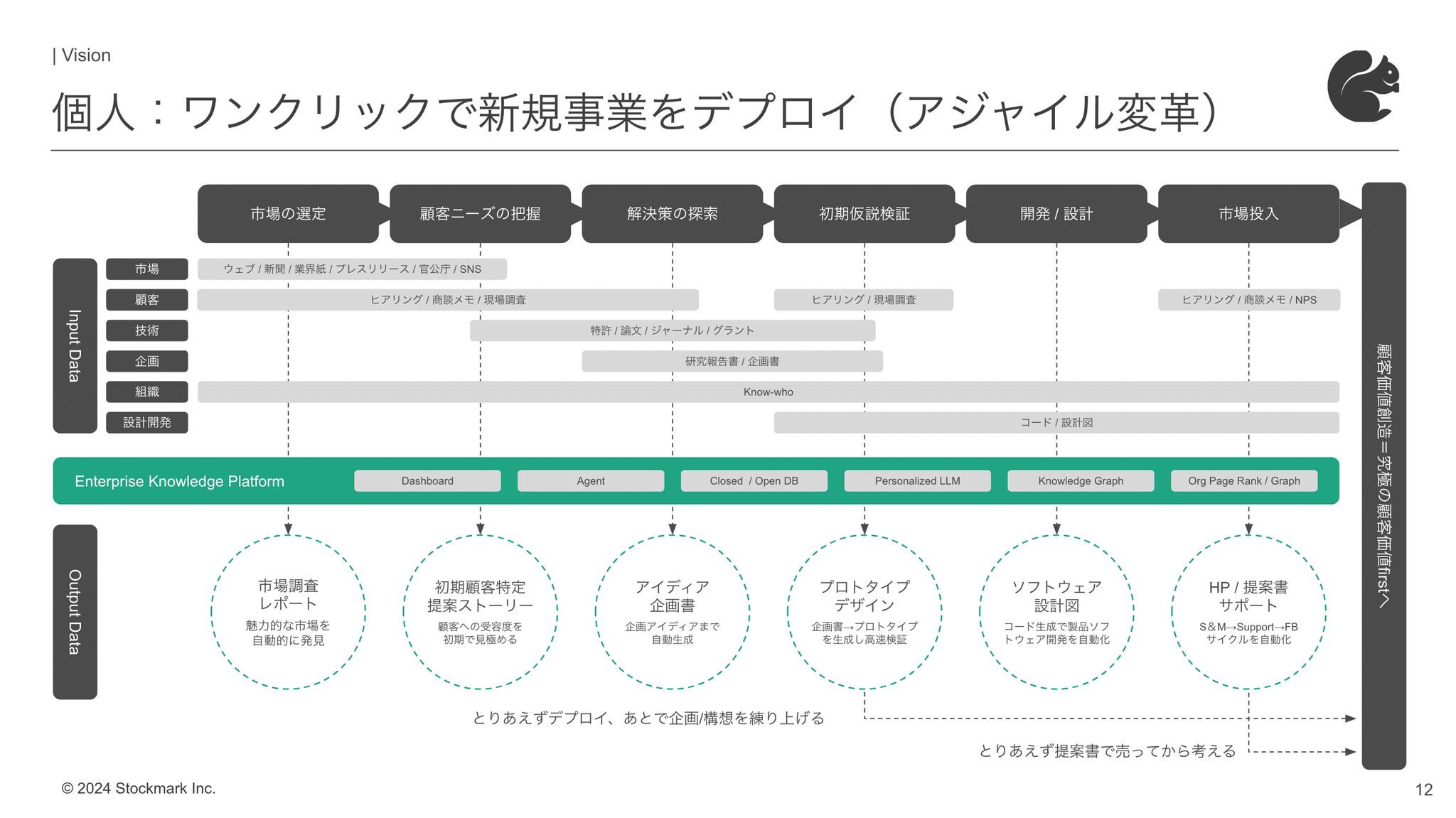
ワンクリックで新規事業をデプロイ
- 新規事業が生まれるプロセスの中で情報収集は出発点に過ぎません。情報収集からニーズ把握、解決策の探索、仮説検証、開発/設計、市場投入の全てのプロセスにAIを用いた仕組みの再発明を行い、ワンクリックで新規事業がデプロイされる世界を実現していきます
👨👨👧👦 組織
Opendataチームのご紹介
私たちストックマーク及びOpendata Unitが目指すのは、Web上のあらゆるビジネス情報を再整理し、ビジネスシーンでのデータ活用業務を自然言語処理AIで総置換することです。そのために、世界中のニュース、企業情報、論文、特許などをWebから収集、抽出、加工して顧客に提供し、企業の製品化・事業化を加速させられるような「オープンデータリサーチサービス」を開発しています。
Opendataチームの取り組み
- 数万オーダーのWebサイトから汎用的に新着情報を収集、抽出するWebクローラー全般の開発と運用
- HTMLやPDFからコンテンツを抽出するMLアプリケーションのプロトタイプ開発
- FaaS/CaaSによる分散処理のパフォーマンスチューニングと監視設計
- MLワークフローとデータプラットフォームの設計/運用
クローリングの仕組み
Stockmarkのプロダクトは、日々発生する膨大なビジネス記事(10万件以上)を常にクローリングし続けています。クローリング対象のURL群を起点として、短期間でURL群を巡回して記事を収集します。収集した記事は、必要なデータのみを取得するため、構造を解析し・余分な情報を削除します。大量の記事に対して、これらの処理を、短期間・低コストで実現するためにAWS Lambdaを利用したスケーラブルなアーキテクチャで実装しています。
ストックマークのアーキテクチャを動画にしました!

技術情報の拡充
ニュース/論文/特許情報などを抽出、配信するためのデータパイプラインを構築



今後のデータ拡充戦略

課題
①Webクローラーの劣化

②コンテンツ抽出のノイズが多い

③Web以外のデータソース拡充

💻技術スタック
開発環境
[開発言語]
Python
[コンテナ]
Docker
[IaC]
Terraform
[クラウド]
AWS, GCP
💼ストックマークの働き方
ビジョンである顧客価値経営(カスタマーセントリック)を体現するために、個人の最大の権限を移譲し、自律分散型、そしてアジリティの高い組織へと進化しています。

🌈 働き方概要
| 制度名 | 概要 |
|---|---|
| 【働き方】フレックスタイム制 | フレックスタイム制(コアタイム10:00-14:00)で自由に働くことができます。 |
| 【働き方】フルリモート | フルリモート可能。関東圏外にお住まいの方も大歓迎です。 |
| 【働き方】副業OK | 副業として他社のプロジェクトに参画することができます。 |
| リファラル採用インセンティブ | 社員紹介経由での採用決定で紹介者にインセンティブが発生します |
🤝募集要項
🧑🤝🧑参考記事
Opendata TeamのインタビューやTech Blogをご紹介します!
価値検証を高速化するために開発チームで意識していること(2023 / 7 / 3)
AIで高速なキュレーションを実現するストックマークのアーキテクチャ
個別最適でプロダクトを作り続けたスタートアップがデータ専任部隊を作ることにした話
【記事まとめ】ストックマークでエンジニアとして働く魅力10選!
ビジネスに必要な情報を世界中から集めるクローリングの仕組みと今後の課題
月間1.6億秒の Lambda x Node.js 利用から得られた知見
Rust+WASMでWebクローラーのXMLパースを高速化
📚その他関連資料
もしよろしければこちらもご覧ください!


ストックマーク テックブログ
エンジニアチームの技術ブログです!
